
Introduction
Since I am enrolled in a university course on machine learning for cybersecurity, I chose the detection of malicious URLs to hone my ML abilities. In Data Science and Preprocessing, there have been numerous papers for this methodology as well as posts about it. I’ll provide links to additional posts and pages for research in references.
Note: this article is an assumption that you have basic knowledge of machine learning, neural networks, and Keras Python Library. I am not a machine learning engineer so if you have any considerations about it you can contact me.
Explanation of the problem
URL is an acronym for Uniform Resource Locator, which is the global address of documents and other World Wide Web resources. A URL is made up of two parts: (1) protocol identification (indicates what protocol to use) (2) resource title (specifies the IP address or the domain name where the resource is located). A colon and two forward slashes separate the protocol identifier and the resource name.[1]

Attackers frequently attempt to change more components of the URL structure to confuse visitors and disseminate their malicious URLs. Malicious URLs are links that harm users. These Websites will route users to resources or pages where attackers can execute codes on users' computers, redirect users to undesirable sites, dangerous websites, or even other phishing sites, or install malware. Malware URLs can also be concealed in relatively safe download links and propagate swiftly through file and message sharing in shared networks. Drive-by Downloads, Phish and Social Engineering, and Spam are some attack strategies that exploit malicious URLs.[2]
Machine learning algorithms are used in our project to classify URLs based on their features and behaviors. The features are derived from URL behaviors. The project’s main contribution is the newly proposed features. The malicious URL detection system includes machine learning algorithms. Multi-Layer Perceptron Neural Network Models are the supervised machine learning algorithms used. This project will make use of the Keras Python library as a project requirement.
Malicious URLs dataset
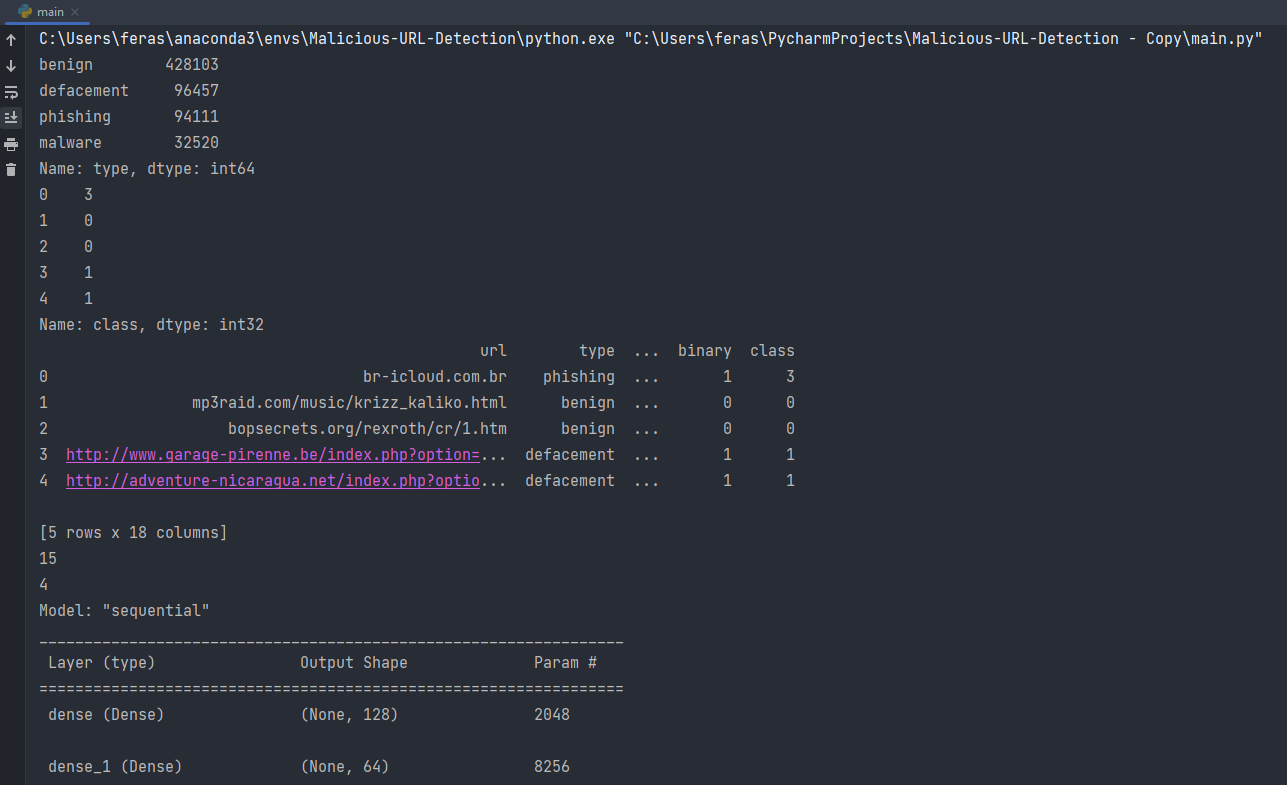
We used a HUGE dataset of 651,191 Malicious URLs, out of which 428103 benign or safe URLs, 96457 defacement URLs, 94111 phishing URLs, and 32520 malware URLs. Check Reference for dataset URL.
Loading dataset
|
|
Visual Look
|
|
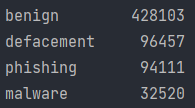
As shown number of type counts is 4 benign, defacement, phishing, and malware URLs
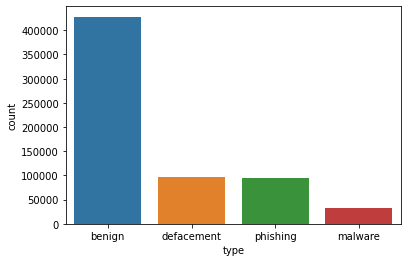
Preprocessing
There are two main steps in this stage
- Data from the dataset CSV is loaded.
- Prepare multi-class classification data for neural network modeling.
- Label encoding for classes
- Extraction and Selection of URL Attributes
|
|
Encoding target labels with value between 0 and n_classes with LabelEncoder can be used to normalize labels.
|
|
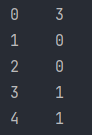
As we can see here after encoding classes into integers for example phishing class will be represented as integer 3 and benign as integer 0 and defacement as integer 1 and malware as integer 2.
Extraction and Selection of URL Attributes
There are numerous approaches we can take here. Because URLs are basically just text, we have a plethora of alternatives for employing Natural Language Processing algorithms. We also have various URL-specific features, such as what is the top-level domain, what is the prefix, and does it have a subdomain. The creation of these features is depending on my knowledge of URLs and counting symbols and lengths for special characters.
| Feature | Description |
|---|---|
| use_of_ip | if URL contain IPv4 or IPv6 |
| url_length | The length of the whole URL |
| url_alphas | A count of the alpha characters within the URL |
| url_digits | A count of the digit/numbers within the URL |
| Numof. | A count of the number of fullstops within the URL |
| Numof- | A count of the number of dahses within the URL |
| Numof% | A count of the number of % within the URL |
| Numof? | A count of the number of ? within the URL |
| NumSensitiveWords | is it contain sensitive words |
| binary_label | A binary label where 0 denotes benign and 1 denotes malicious (i.e a combination of all other classes) |
| hostname_length | length of hostname |
More features (attributes) can be added, as well as host-based features. For example, check whois lookup, HTTP headers, etc., but lexical features are sufficient for this project.
The technical details for this features creation will be in source code section ,let’s continue with preprocessing step.
|
|
Here we just add to features (check source code for more details about each one)
|
|
Classes are represented as numbers in training data; ‘to categorical’ will convert those numbers into binary matrix suitable for use with models.
ML architecture
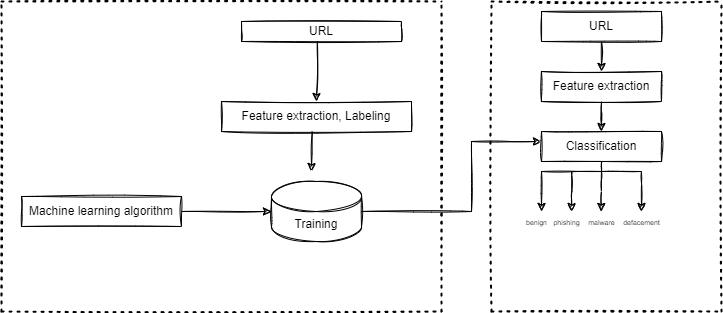
Figure above depicts the proposed machine learning-based dangerous URL detection system. The machine learning-based malicious URL detection approach has two stages: training and detection.
- Phase of training: To detect harmful URLs, both malicious and clean URLs must be collected. The malicious and clean URLs are then accurately tagged before proceeding to attribute collection. These features will be the most useful when figuring out what URLs are safe and which are dangerous. The specifics of these characteristics will be provided in this project. Eventually, this dataset is separated into two subsets: training data for machine deep learning and testing data for the testing procedure. If the machine learning model’s classification performance is sufficiently good, it will be employed in the detection stage.
- Phase of detection: The detection phase is done on each input URL. The URL will first go through the attribute extraction process. Following that, these attributes are fed into the classifier, which determines if the URL is either bengin,defacment,malware or phishing.
|
|
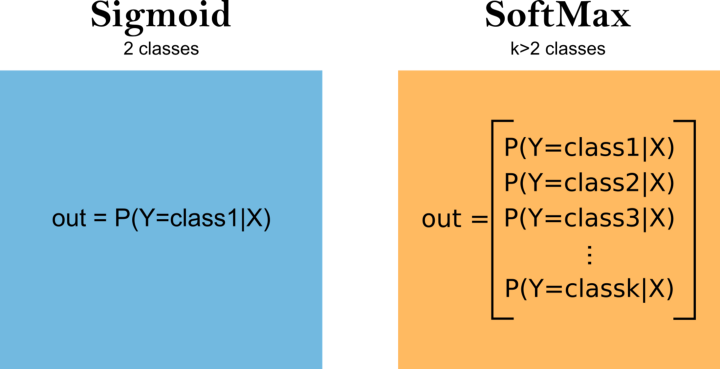
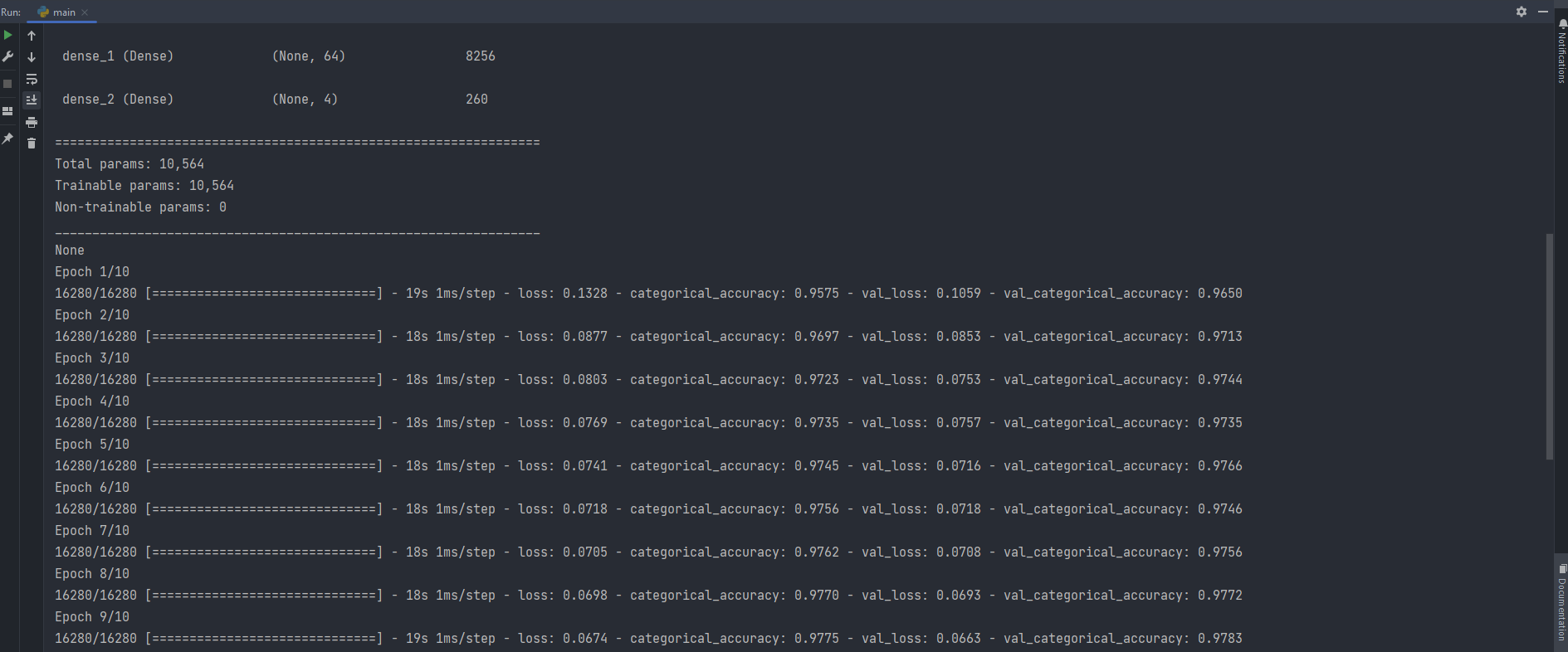
Because each sample contains 15 inputs and 4 outputs, the network requires an input layer in the first hidden layer that expects 15 inputs supplied by the “input dim” argument and four nodes in the output layer. In the hidden layer, we will employ the well-known relu activation function. The hidden layer contains 128 nodes that were selected by try and error. The second hidden layer contains 64 nodes. We’ll use categorical cross-entropy loss and the Adam version of stochastic gradient descent to fit the model. The last hidden layer is take 4 output which is our multi classess and softmax used which is used to multiclass problems.
Source Code
You can find source code in my Github repositoy link
Output with findings
In the source code i will increase epoch three times and other will set to default from keras like batching size, etc…
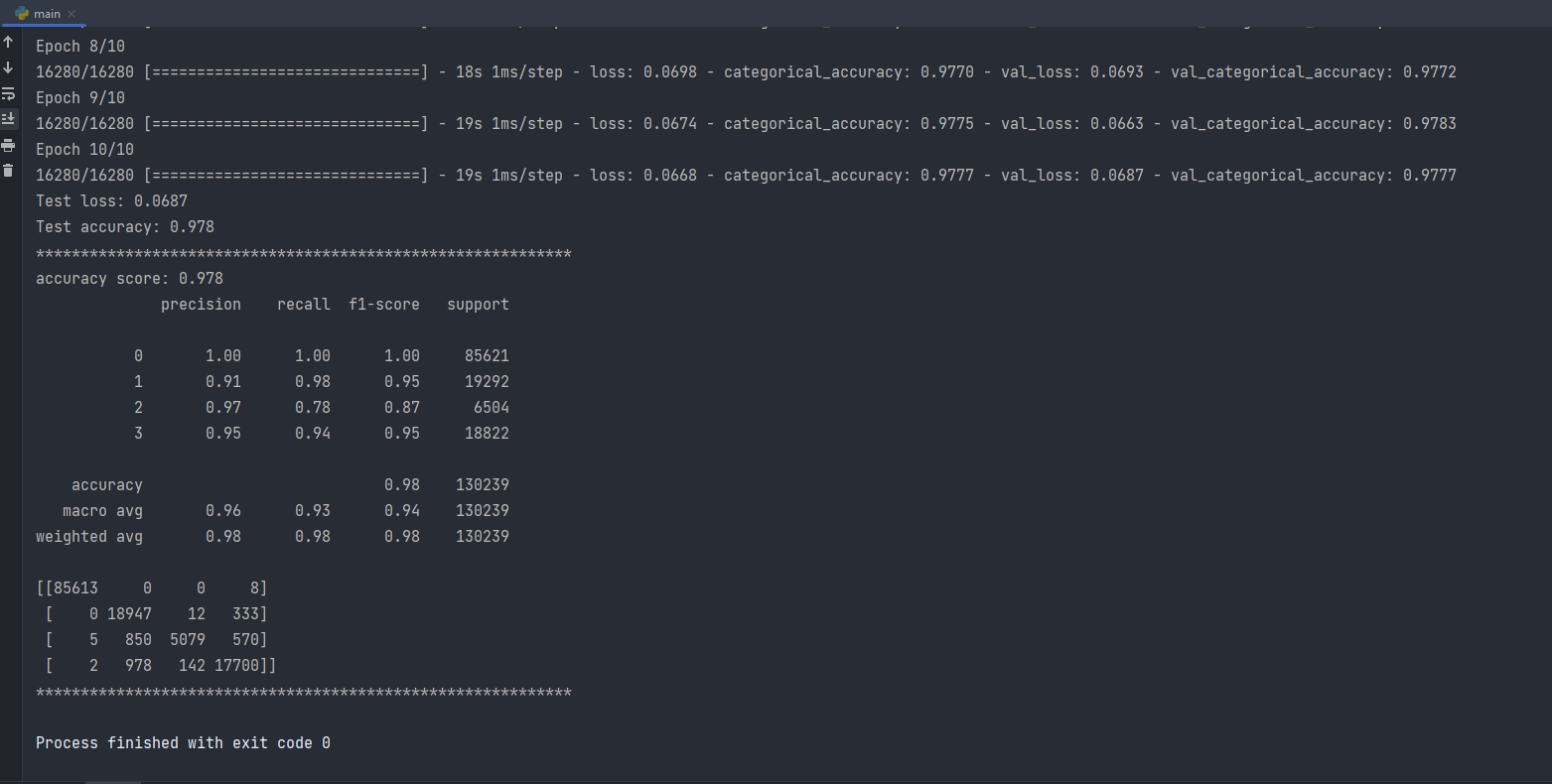
Epoch = 10 —> Test loss: 0.0687, Test accuracy: 0.978, precision: 0.96, recall: 0.93
Plot
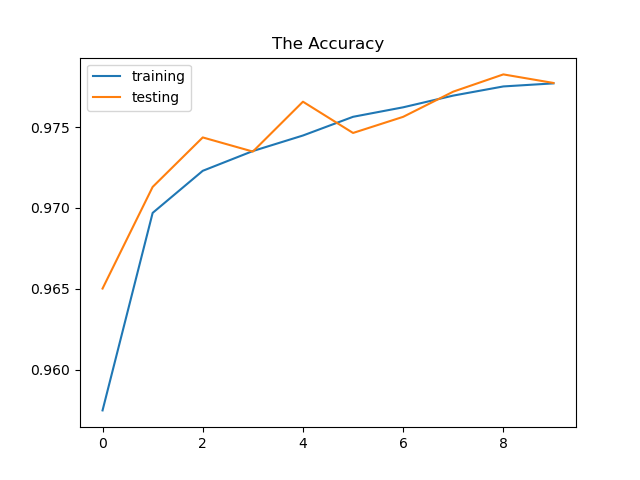
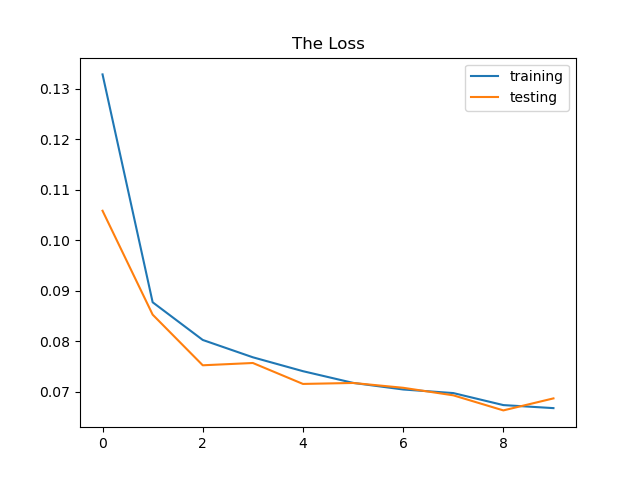
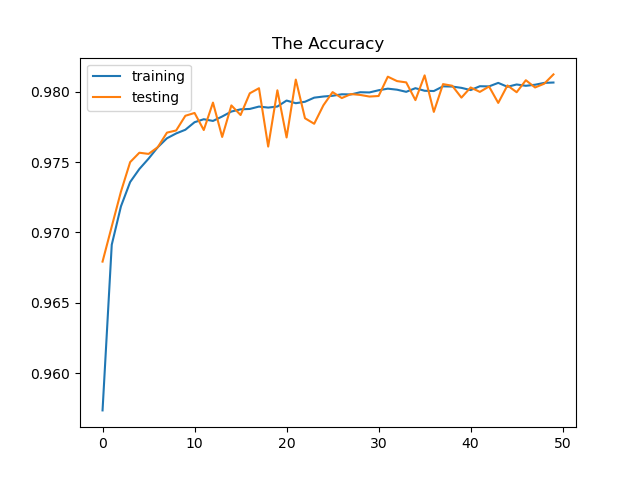
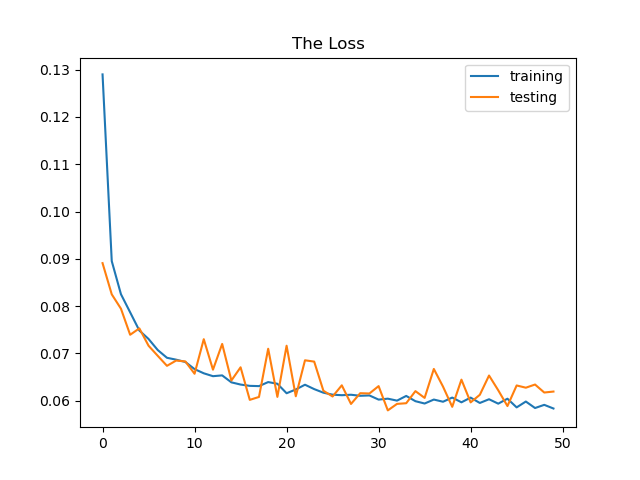
Epoch = 50 —> Test loss: 0.0687, Test accuracy: 0.978, precision: 0.96, recall: 0.93
Epoch= 100 —> Test loss:: 0.0619 , Test accuracy:0.981 , precision:0.96, recall: 0.94
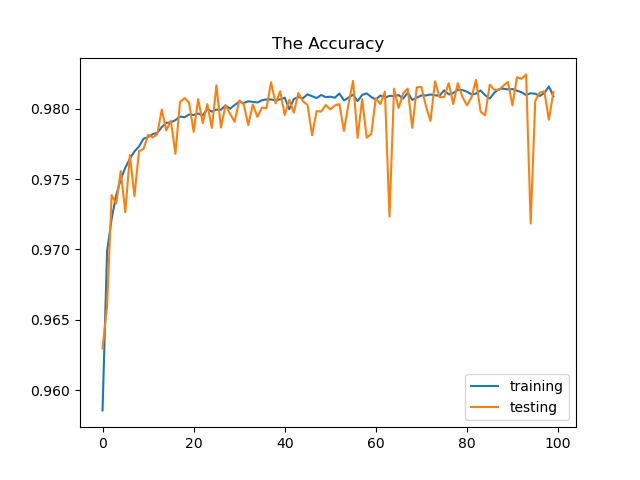
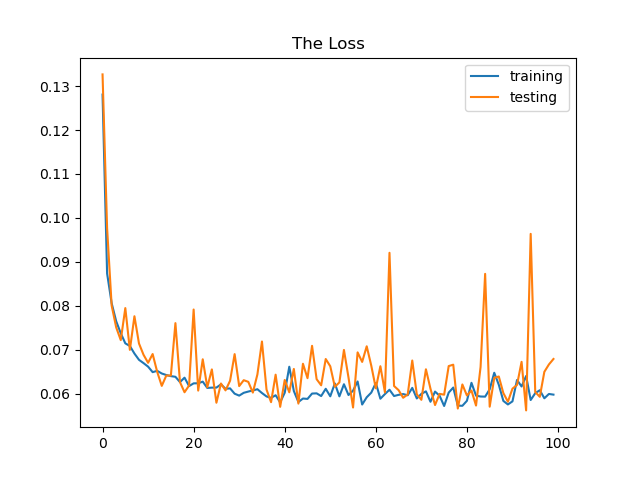
Findings from all three outputs:
The neural network’s weights are adjusted more frequently as the number of epochs increase, and the curve shifts from underfitting to optimum to overfitting . We can see from epoch 10 plot that is the curve is consider underfitting and when we increase it to 50 it shift to more optimal curve but when add and increase epoch to 100 the curve looking in overfit situation.
References
- D. Sahoo, C. Liu, S.C.H. Hoi, “Malicious URL Detection using Machine Learning: A Survey”. CoRR, abs/1701.07179, 2017[1]
- M. Khonji, Y. Iraqi, and A. Jones, “Phishing detection: a literature survey,” IEEE Communications Surveys & Tutorials, vol. 15, no. 4, pp. 2091–2121, 2013[2]
- https://www.datarevenue.com/en-blog/machine-learning-project-architecture
- https://faroit.com/keras-docs/1.2.0/
- https://www.kaggle.com/datasets/sid321axn/malicious-urls-dataset
- Multi-label classification with keras
- Multi-Label Classification with Deep Learning
- how-to-implement-multiclass-classification-using-keras
- https://machinelearningmastery.com/softmax-activation-function-with-python/